In order to use it to load CSV data, it is invoked by providing the connection information for your HBase cluster, the name of the table to load data into, and the path to the CSV file or files. Note that all CSV files to be loaded must have the ‘.csv’ file extension (this is because arbitrary SQL scripts with the ‘.sql’ file extension
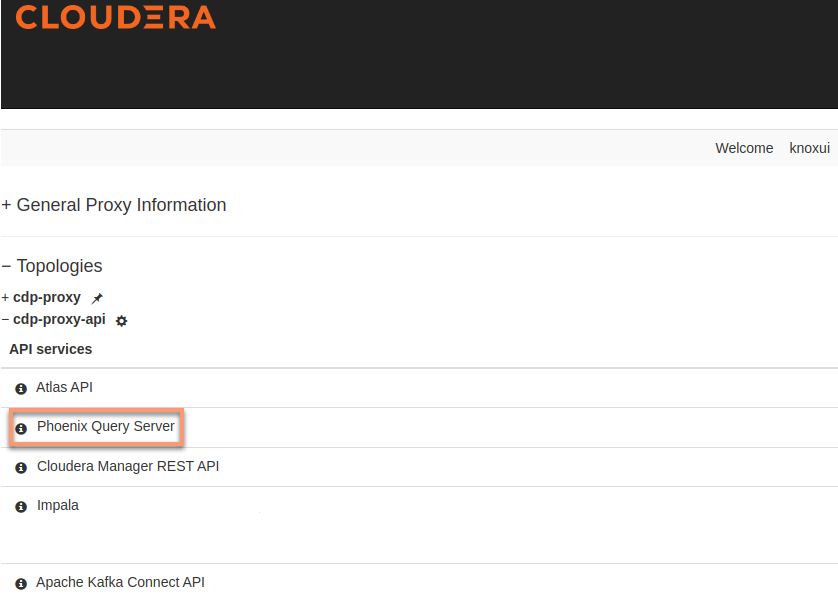
Connect to Phoenix Query Server through Apache Knox | CDP Private Cloud
With builtin dynamic metadata querying, you can work with and analyze Phoenix data using native data types. Install the CData JDBC Driver for Phoenix. Download the CData JDBC Driver for Phoenix installer, unzip the package, and run the JAR file to install the driver. Start a Spark Shell and Connect to Phoenix Data

Source Image: www.pinterest.com
Download Image
Description. LOAD DATA statement loads the data into a Hive serde table from the user specified directory or file. If a directory is specified then all the files from the directory are loaded. If a file is specified then only the single file is loaded. Additionally the LOAD DATA statement takes an optional partition specification.
Source Image: www.sqlshack.com
Download Image
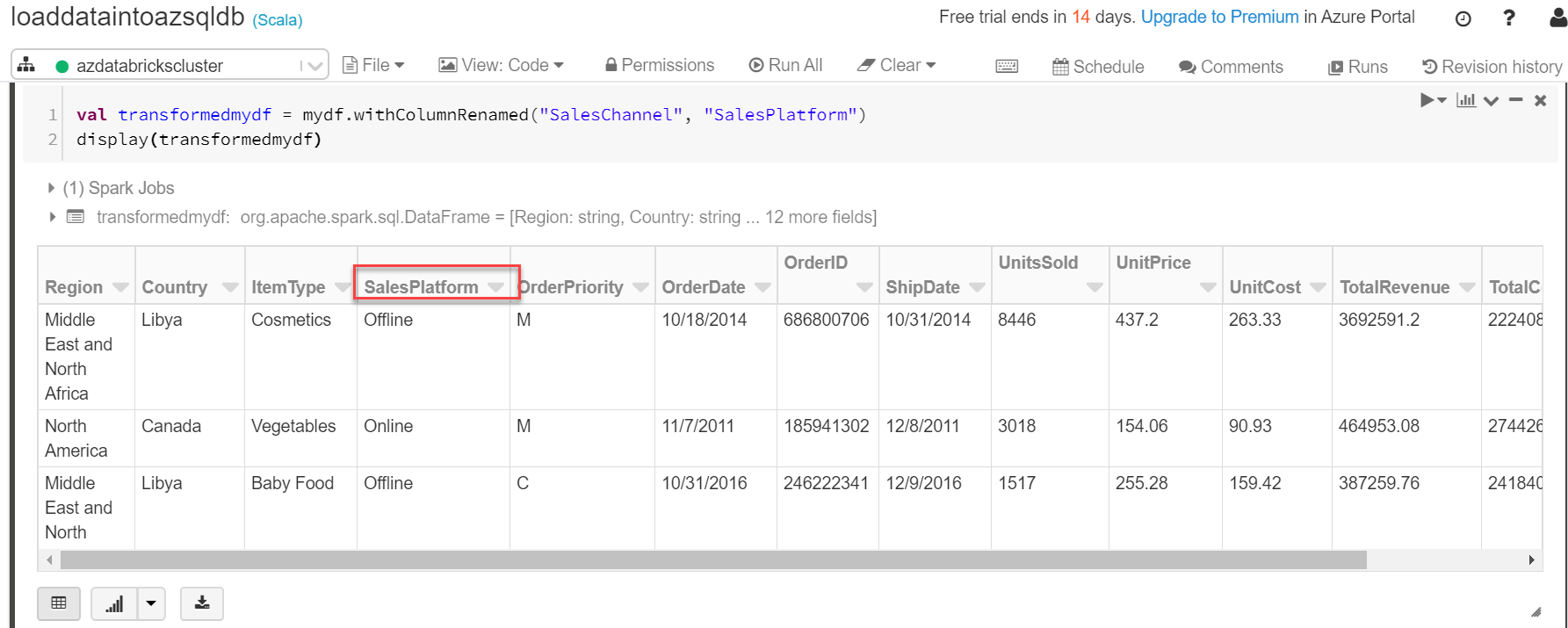
Apache Phoenix and HBase: Past, Present and Future of SQL over HBase | PPT In the first part of this series, we looked at advances in leveraging the power of relational databases “at scale” using Apache Spark SQL and DataFrames . We will now do a simple tutorial based on a real-world dataset to look at how to use Spark SQL. We will be using Spark DataFrames, but the focus will be more on using SQL.
Source Image: www.databricks.com
Download Image
How To Load Data From Phoenix Using Spark Sql
In the first part of this series, we looked at advances in leveraging the power of relational databases “at scale” using Apache Spark SQL and DataFrames . We will now do a simple tutorial based on a real-world dataset to look at how to use Spark SQL. We will be using Spark DataFrames, but the focus will be more on using SQL. Spark SQL brings native support for SQL to Spark and streamlines the process of querying data stored both in RDDs (Spark’s distributed datasets) and in external sources. Spark SQL conveniently blurs the lines between RDDs and relational tables. Unifying these powerful abstractions makes it easy for developers to intermix SQL commands querying
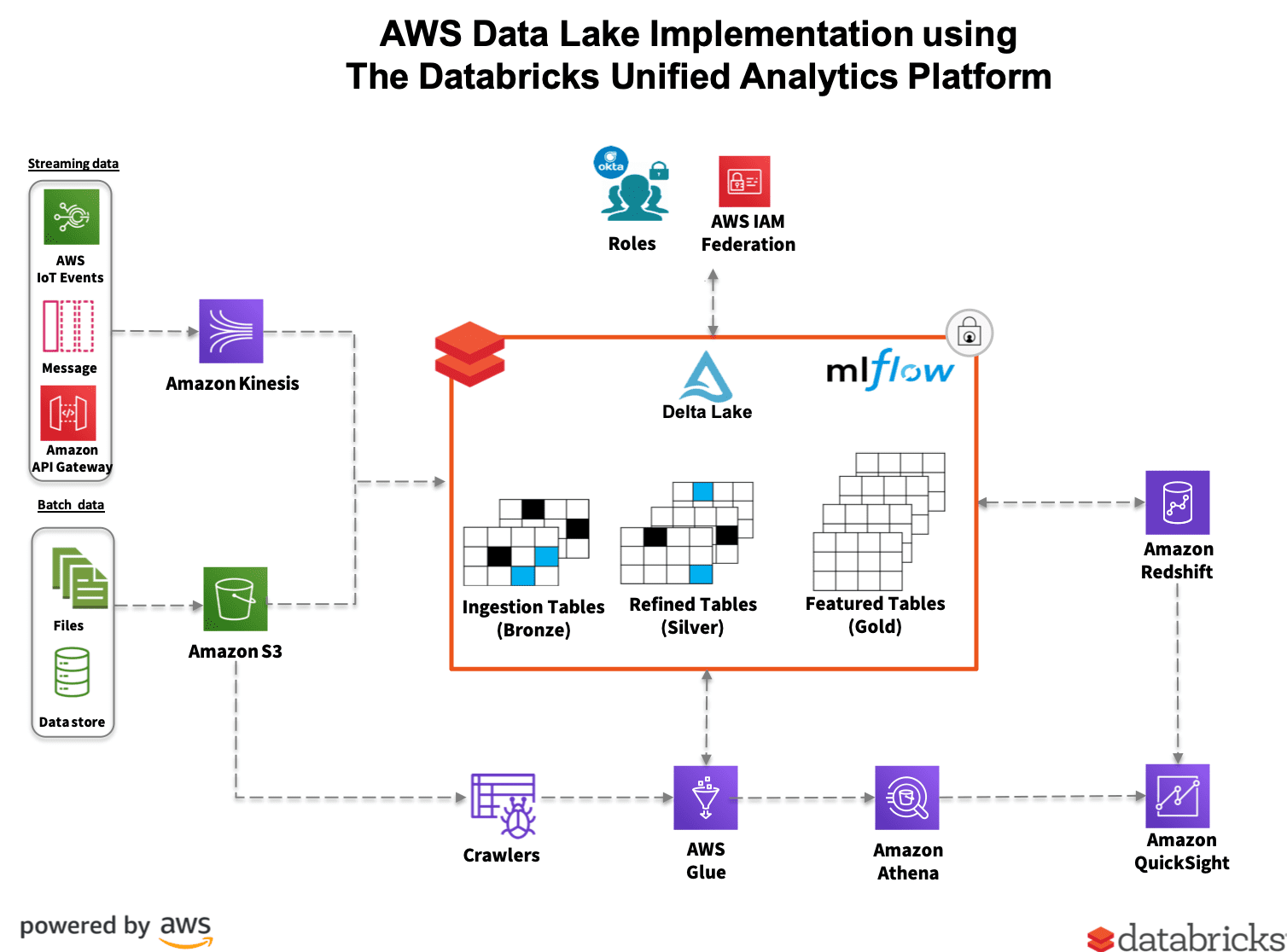
How Delta Lake 0.7.0 and Apache Spark 3.0 Combine to Support Metatore-defined Tables and SQL DDL – The Databricks Blog
Mar 2, 2024The spark.sql is a module in Spark that is used to perform SQL-like operations on the data stored in memory. You can either leverage using programming API to query the data or use the ANSI SQL queries similar to RDBMS. You can also mix both, for example, use API on the result of an SQL query. Following are the important classes from the SQL module. Sqoop(RDBMS) to hdfs/HBase/Phoenix

Source Image: www.linkedin.com
Download Image
Apache Phoenix – another query engine with a SQL interface fine tuned for performance with HBase – Sitecore, AWS, Big Data Blogs Mar 2, 2024The spark.sql is a module in Spark that is used to perform SQL-like operations on the data stored in memory. You can either leverage using programming API to query the data or use the ANSI SQL queries similar to RDBMS. You can also mix both, for example, use API on the result of an SQL query. Following are the important classes from the SQL module.

Source Image: mohdnaeem.wordpress.com
Download Image
Connect to Phoenix Query Server through Apache Knox | CDP Private Cloud In order to use it to load CSV data, it is invoked by providing the connection information for your HBase cluster, the name of the table to load data into, and the path to the CSV file or files. Note that all CSV files to be loaded must have the ‘.csv’ file extension (this is because arbitrary SQL scripts with the ‘.sql’ file extension
Source Image: docs.cloudera.com
Download Image
Apache Phoenix and HBase: Past, Present and Future of SQL over HBase | PPT Description. LOAD DATA statement loads the data into a Hive serde table from the user specified directory or file. If a directory is specified then all the files from the directory are loaded. If a file is specified then only the single file is loaded. Additionally the LOAD DATA statement takes an optional partition specification.

Source Image: www.slideshare.net
Download Image
Spark select – Spark dataframe select – Projectpro A DataFrame is a Dataset organized into named columns. It is conceptually equivalent to a table in a relational database or a data frame in R/Python, but with richer optimizations under the hood. DataFrames can be constructed from a wide array of sources such as: structured data files, tables in Hive, external databases, or existing RDDs. The

Source Image: www.projectpro.io
Download Image
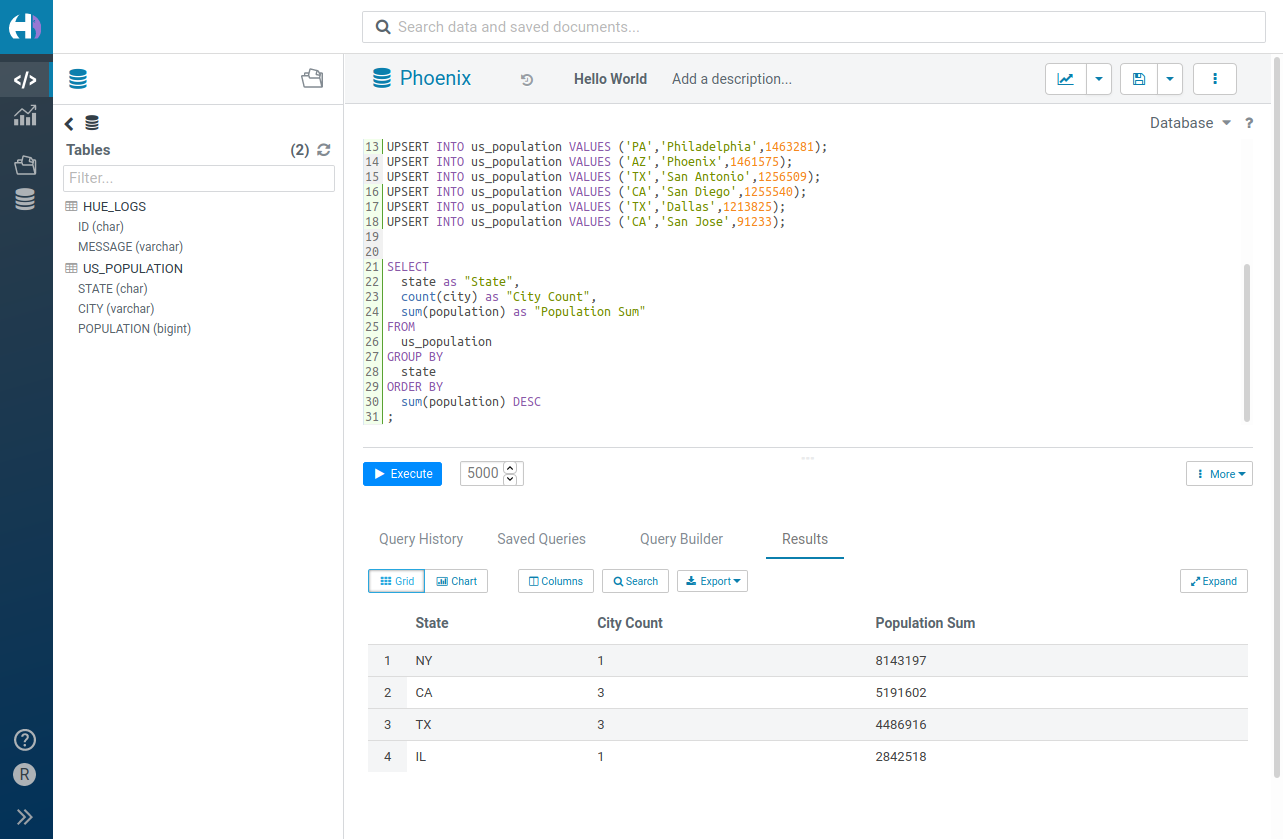
Hue – The open source SQL Assistant for Data Warehouses In the first part of this series, we looked at advances in leveraging the power of relational databases “at scale” using Apache Spark SQL and DataFrames . We will now do a simple tutorial based on a real-world dataset to look at how to use Spark SQL. We will be using Spark DataFrames, but the focus will be more on using SQL.
Source Image: gethue.com
Download Image
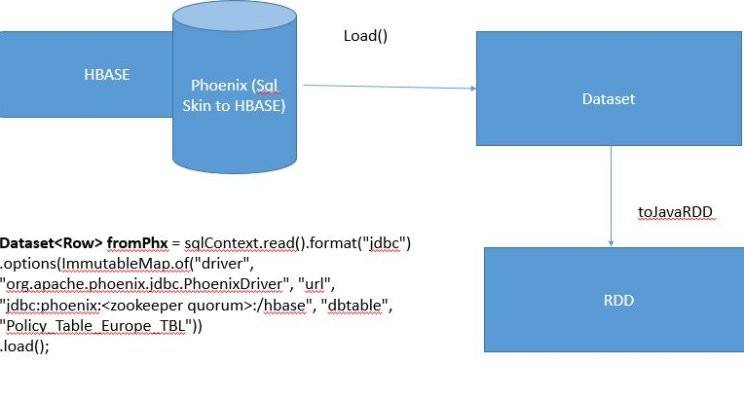
Fetch Record from Phoenix table to Dataset using Spark(Java) Spark SQL brings native support for SQL to Spark and streamlines the process of querying data stored both in RDDs (Spark’s distributed datasets) and in external sources. Spark SQL conveniently blurs the lines between RDDs and relational tables. Unifying these powerful abstractions makes it easy for developers to intermix SQL commands querying
Source Image: www.linkedin.com
Download Image
Apache Phoenix – another query engine with a SQL interface fine tuned for performance with HBase – Sitecore, AWS, Big Data Blogs
Fetch Record from Phoenix table to Dataset using Spark(Java) With builtin dynamic metadata querying, you can work with and analyze Phoenix data using native data types. Install the CData JDBC Driver for Phoenix. Download the CData JDBC Driver for Phoenix installer, unzip the package, and run the JAR file to install the driver. Start a Spark Shell and Connect to Phoenix Data
Apache Phoenix and HBase: Past, Present and Future of SQL over HBase | PPT Hue – The open source SQL Assistant for Data Warehouses A DataFrame is a Dataset organized into named columns. It is conceptually equivalent to a table in a relational database or a data frame in R/Python, but with richer optimizations under the hood. DataFrames can be constructed from a wide array of sources such as: structured data files, tables in Hive, external databases, or existing RDDs. The
